
Hi! I’m a 3rd year undergrad at UC Berkeley studying Electrical Engineering and Computer Science (EECS).
I’m broadly interested in Reinforcement Learning and Robot Learning. Currently, I work on Policy Extraction for generative offline RL algorithms, and offline-to-online RL for robotics at BAIR, in professor Sergey Levine’s group. I’ve also had the chance to work on Test-Time policy improvement methods as an OpenAI research fellow, and online RL for VLA exploration and post-training with the GEAR team at NVIDIA. I’ll also be working on RL research as a QR at Jump Trading this summer. Previously, I’ve built LLM Infra with the ChipNemo team at NVIDIA, and worked on high-speed simulations on FPGAs for Robotaxi charging at Tesla. Outside research, I spend my time with friends at Cal Launchpad, and playing IM basketball.
If you’d like to chat, please reach out at [andypeng at berkeley dot edu].
Publications
|
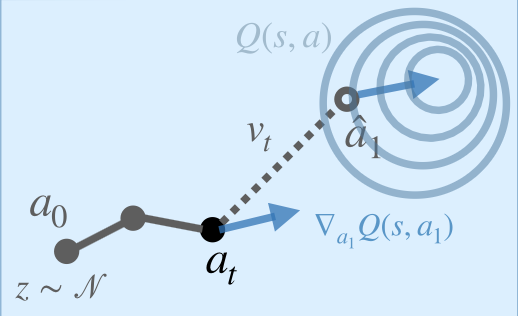
Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning Zhiyuan Zhou, Andy Peng, Charles Xu, Qiyang Li, Jost Tobias Springenberg, Kevin Frans, Sergey LevinePreprint, 2026 [paper] [website] |
|
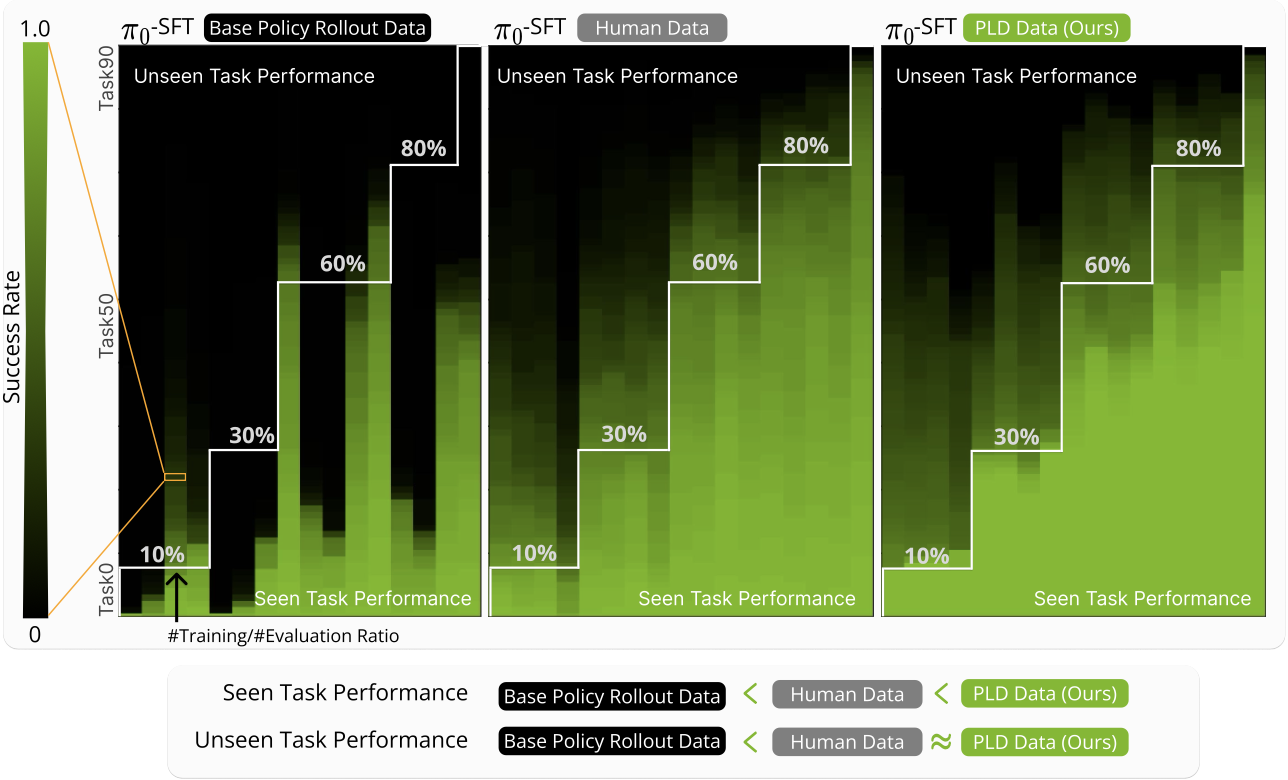
Self-improving Vision-Language-Action models with data generation via Residual RL Wenli Xiao*, Haotian Lin*, Andy Peng, Haoru Xue, Tairan He, Yuqi Xie, Fengyuan Hu, Jimmy Wu, Zhengyi Luo, Linxi "Jim" Fan, Guanya Shi, Yuke Zhu,International Conference on Learning Representations (ICLR), 2026 [paper] [website] |

|
Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data Zhiyuan Zhou*, Andy Peng*, Qiyang Li, Sergey Levine, Aviral KumarInternational Conference on Learning Representations (ICLR), 2025 [paper] [website] [code] |